Criando PDFs com PyFPDF e Python
O PyFPDF ou FPDF for Python . O pacote PyFPDF é na verdade uma porta do pacote "Free" -PDF que foi escrito em PHP. Não há um lançamento deste projeto há alguns anos, mas houve confirmações no seu repositório Github, portanto ainda há algum trabalho sendo feito no projeto. O pacote PyFPDF suporta Python 2.7 e Python 3.4+.
Este artigo não será exaustivo em sua cobertura do pacote PyFPDF. No entanto, ele cobrirá mais do que o suficiente para você começar a usá-lo de forma eficaz. Observe que há um pequeno livro sobre PyFPDF chamado “Python does PDF: pyFPDF” de Edwood Ocasio no Leanpub, se você quiser aprender mais sobre a biblioteca do que o que é abordado neste capítulo ou na documentação do pacote.
Instalação
A instalação do PyFPDF é fácil, pois foi projetada para funcionar com o pip. Aqui está como:
python -m pip install fpdf
No momento da redação deste documento, este comando instalava a versão 1.7.2 no Python 3.6 sem problemas. Você notará quando instalar este pacote que ele não possui dependências, o que é bom.
Uso básico
Agora que você tem o PyFPDF instalado, vamos tentar usá-lo para criar um PDF simples. Abra seu editor Python e crie um novo arquivo chamado ** simple_demo.py **. Em seguida, insira o seguinte código nele:
# simple_demo.py de fpdf import FPDF pdf = FPDF ( ) pdf. add_page ( ) pdf. set_font ( "Arial" , tamanho = 12 ) pdf. célula ( 200 , 10 , txt = "Bem-vindo ao Python!" , ln = 1 , align = "C" ) pdf. saída ( "simple_demo.pdf" )
O primeiro item sobre o qual precisamos falar é a importação. Aqui nós importamos o FPDF classe do fpdf pacote. Os padrões desta classe são criar o PDF no modo Retrato, usar milímetros em sua unidade de medida e usar o tamanho da página A4. Se você quisesse ser explícito, poderia escrever a linha de instanciação assim:
pdf = FPDF ( orientação = 'P' , unidade = 'mm' , formato = 'A4' )
Não sou fã de usar a letra 'P' para dizer à classe qual é a sua orientação. Você também pode usar 'L' se preferir paisagem em vez de retrato.
O pacote PyFPDF suporta 'pt', 'cm' e 'in' como unidades de medida alternativas.
Se você for mergulhar na fonte, verá que o pacote PyFPDF suporta apenas os seguintes tamanhos de página:
- A3
- A4
- A5
- carta
- legal
Isso é um pouco limitante em comparação com o ReportLab, onde você tem vários tamanhos adicionais suportados e pode definir o tamanho da página para algo personalizado também.
De qualquer forma, o próximo passo é criar uma página usando o método add_page . Em seguida, definimos a fonte da página através do método set_font . Você notará que passamos o nome da família da fonte e o tamanho que queremos. Você também pode definir o estilo da fonte com o argumento style . Se você quiser fazer isso, observe que é preciso uma string como 'B' para negrito ou 'BI' para negrito e itálico .
Em seguida, criamos uma célula com 200 milímetros de largura e 10 milímetros de altura. Uma célula é basicamente um fluxo que contém texto e pode ter uma borda ativada. Ele será dividido automaticamente se a quebra automática de página estiver ativada e a célula ultrapassar o limite de tamanho da página. O parâmetro txt é o texto que você deseja imprimir no PDF. O parâmetro ln diz ao PyFPDF para adicionar uma quebra de linha, se definido como um, que é o que fazemos aqui. Finalmente, podemos definir o alinhamento do texto para ser alinhado (o padrão) ou centralizado ('C'). Nós escolhemos o último aqui.
Finalmente, salvamos o documento em disco chamando o método de saída com o caminho para o arquivo que queremos salvar.
Quando executei esse código, acabei com um PDF parecido com este:
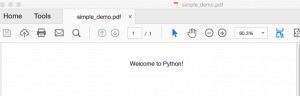
Agora vamos aprender um pouco sobre como o PyFPDF funciona com fontes.
Trabalhando com fontes
O PyFPDF possui um conjunto de fontes principais codificadas em sua classe FPDF:
eu . core_fonts = { 'courier' : 'Courier' , 'courierB' : 'Courier-Bold' , 'courierBI' : 'Courier-BoldOblique' , 'courierI' : 'Courier-Oblique' , 'helvetica' : 'Helvetica' , ' helveticaB ' : ' Helvetica-Bold ' , ' helveticaBI ' : ' Helvetica-BoldOblique ' , ' helveticaI ' : ' Helvetica-Oblique ' , 'times' : 'Times-Roman' , 'timesB' : 'Times-Bold' , 'timesBI' : 'Times-BoldItalic' , 'timesI' : 'Times-Italic' , 'zapfdingbats' : 'ZapfDingbats }}
Você observará que o Arial não está listado aqui, embora o tenhamos usado no exemplo anterior. Arial está sendo remapeado para Helvetica no código-fonte real, então você não está realmente usando Arial. De qualquer forma, vamos aprender como você pode alterar fontes usando o PyFPDF:
# change_fonts.py de fpdf import FPDF def change_fonts ( ) : pdf = FPDF ( ) pdf. add_page ( ) font_size = 8 para fonte em pdf. core_fonts : se houver ( [ letra por letra na fonte se letra. isupper ( ) ] ) : # pule esta fonte continue pdf. set_font ( fonte, tamanho = tamanho da fonte ) txt = "Nome da fonte: {} - {} pts" . formato (fonte, tamanho da fonte ) pdf. célula ( 0 , 10 , txt = txt, ln = 1 , alinhar = "C" ) font_size + = 2 pdf. saída ( "change_fonts.pdf" ) se __name__ == '__main__' : change_fonts ( )
Aqui, criamos uma função simples chamada change_fonts e, em seguida, criamos uma instância da classe FPDF. O próximo passo é criar uma página e fazer um loop sobre as fontes principais. Quando tentei isso, descobri que o PyFPDF não considera os nomes de variantes de suas fontes principais como fontes válidas (por exemplo, helveticaB, helveticaBI, etc.). Portanto, para pular essas variantes, criamos uma compreensão da lista e verificamos os caracteres maiúsculos no nome da fonte. Se houver, pularemos essa fonte. Caso contrário, definimos a fonte e o tamanho da fonte e escrevemos. Também aumentamos o tamanho da fonte em dois pontos a cada vez no loop. Se você deseja alterar a cor da fonte, pode chamar set_text_color e passar o valor RGB necessário.
O resultado da execução desse código se parece com o seguinte:

Eu gosto de como é fácil alterar fontes no PyFPDF. No entanto, o número de fontes principais é bem pequeno. Você pode adicionar fontes TrueType, OpenType ou Type1 usando PyFPDF, através do método add_font . Este método utiliza os seguintes argumentos:
- família (família de fontes)
- estilo (estilo de fonte)
- fname (nome do arquivo de fonte ou caminho completo para o arquivo de fonte)
- uni (sinalizador TTF Unicode)
O exemplo que a documentação do PyFPDF usa é o seguinte:
pdf. add_font ( 'DejaVu' , '' , 'DejaVuSansCondensed.ttf' , uni = True )
Você chamaria ** add_font ** antes de tentar usá-lo através do método ** set_font **. Eu tentei isso no Windows e recebi um erro, pois o Windows não conseguiu encontrar essa fonte, o que eu esperava. Essa é uma maneira realmente simples de adicionar fontes e provavelmente funcionará. Observe que ele usa os seguintes caminhos de pesquisa:
- FPDF_FONTPATH
- SYSTEM_TTFONTS
Elas parecem constantes definidas no seu ambiente ou no próprio pacote PyFPDF. A documentação não explica como eles são definidos ou modificados; no entanto, se você observar atentamente a API e o código-fonte, parece que você precisará fazer o seguinte no início do seu código:
importar fpdf fpdf. SYSTEM_TTFONTS = '/ caminho / para / sistema / fontes'
O SYSTEM_TTFONTS é definido como None por padrão, caso contrário.
Desenhando
O pacote PyFPDF possui suporte limitado ao desenho. Você pode desenhar linhas, elipses e retângulos. Vamos dar uma olhada em como desenhar linhas primeiro:
# draw_lines.py de fpdf import FPDF def draw_lines ( ) : pdf = FPDF ( ) pdf. add_page ( ) pdf. linha ( 10 , 10 , 10 , 100 ) pdf. set_line_width ( 1 ) pdf. set_draw_color ( 255 , 0 , 0 ) pdf. linha ( 20 , 20 , 100 , 20 ) pdf. saída ( 'draw_lines.pdf' ) se __name__ == '__main__' : draw_lines ( )
Aqui chamamos o método de linha e passamos dois pares de coordenadas x / y. Como a largura da linha é 0,2 mm, aumentamos para 1 mm para a segunda linha chamando o método set_line_width . Também definimos a cor da segunda linha chamando set_draw_color para um valor RGB equivalente a vermelho. A saída é assim:
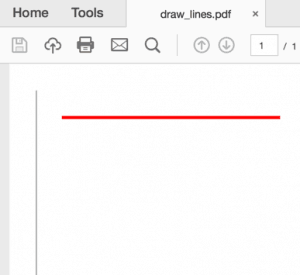
Agora podemos seguir em frente e desenhar algumas formas:
# draw_shapes.py de fpdf import FPDF def draw_shapes ( ) : pdf = FPDF ( ) pdf. add_page ( ) pdf. set_fill_color ( 255 , 0 , 0 ) pdf. elipse ( 10 , 10 , 10 , 100 , 'F' ) pdf. set_line_width ( 1 ) pdf. set_fill_color ( 0 , 255 , 0 ) pdf. rect ( 20 , 20 , 100 , 50 ) pdf. saída ( 'draw_shapes.pdf' ) se __name__ == '__main__' : draw_shapes ( )
Quando você desenha uma forma como uma elipse ou um retângulo , precisará passar nas coordenadas x e y que representam o canto superior esquerdo do desenho. Então você vai querer passar na largura e altura da forma. O último argumento que você pode passar é para o estilo que pode ser “D” ou uma sequência vazia (padrão), “F” para preenchimento ou “DF” para desenho e preenchimento. Neste exemplo, preenchemos a elipse e usamos o padrão para o retângulo. O resultado acaba sendo assim:
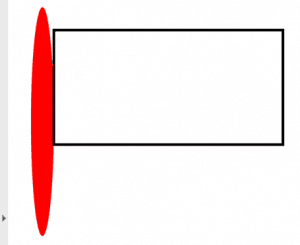
Agora vamos aprender sobre o suporte a imagens.
Adicionando imagens
O pacote PyFPDF suporta a adição de formatos JPEG, PNG e GIF ao seu PDF. Se você tentar usar um GIF animado, apenas o primeiro quadro será usado. Também é importante notar que, se você adicionar a mesma imagem várias vezes ao documento, o PyFPDF será inteligente o suficiente para incorporar apenas uma cópia real da imagem. Aqui está um exemplo muito simples de adicionar uma imagem a um PDF usando PyFPDF:
# add_image.py de fpdf import FPDF def add_image ( caminho da imagem ) : pdf = FPDF ( ) pdf. add_page ( ) pdf. imagem ( caminho_da_imagem, x = 10 , y = 8 , w = 100 ) pdf. set_font ( "Arial" , tamanho = 12 ) pdf. ln ( 85 ) # move 85 para baixo pdf. célula ( 200 , 10 , txt = "{}" . formato ( caminho_da_imagem ) , ln = 1 ) pdf. saída ("add_image.pdf" ) se __name__ == '__main__' : add_image ( 'snakehead.jpg' )
O novo trecho de código aqui é a chamada para o método de imagem . Sua assinatura se parece com o seguinte:
imagem ( nome, x = Nenhum , y = Nenhum , w = 0 , h = 0 , tipo = '' , link = '' )
Você especifica o caminho do arquivo de imagem, as coordenadas xey e a largura e altura. Se você especificar apenas a largura ou a altura, a outra será calculada para você e tentará manter as proporções originais da imagem. Você também pode especificar o tipo de arquivo explicitamente, caso contrário, ele será calculado a partir do nome do arquivo. Finalmente, você pode adicionar um link / URL ao adicionar a imagem.
Ao executar esse código, você verá algo como o seguinte:

Agora vamos aprender como o PyFPDF suporta a criação de documentos de várias páginas.
Documentos de várias páginas
O PyFPDF tinha o suporte a várias páginas ativado por padrão. Se você adicionar células suficientes a uma página, ela criará automaticamente uma nova página e continuará adicionando seu novo texto à próxima página. Aqui está um exemplo simples:
# multipage_simple.py de fpdf import FPDF def multipage_simple ( ) : pdf = FPDF ( ) pdf. set_font ( "Arial" , tamanho = 12 ) pdf. add_page ( ) line_no = 1 para i no intervalo ( 100 ) : pdf. célula ( 0 , 10 , txt = "Linha # {}" . formato ( line_no ) , ln = 1 ) line_no + = 1 pdf. saída ( "multipage_simple.pdf" ) se __name__ == '__main__' : multipage_simple ( )
Tudo isso faz é criar 100 linhas de texto. Quando corri esse código, acabei com um PDF que continha 4 páginas de texto.
Cabeçalhos e Rodapés
O pacote PyFPDF possui suporte interno para adicionar cabeçalhos, rodapés e números de páginas. A classe FPDF só precisa ser subclassificada e os métodos de cabeçalho e rodapé substituídos para fazê-los funcionar. Vamos dar uma olhada:
# header_footer.py de fpdf import FPDF classe CustomPDF ( FPDF ) : def header ( self ) : # Configure um logotipo próprio . auto- imagem ( 'snakehead.jpg' , 10 , 8 , 33 ) . set_font ( 'Arial' , 'B' , 15 ) # Adicione um endereço próprio . célula ( 100 ) auto . células ( 0 , 5 , 'Mike Driscoll' , ln = 1 ) auto . célula ( 100 ) auto . células ( 0 , 5 , '123 American Way' , ln = 1 ) auto . célula ( 100 ) auto . célula ( 0 , 5 , 'Qualquer cidade, EUA', ln = 1 ) # Quebra de linha própria . ln ( 20 ) def rodapé ( auto ) : auto . set_y ( -10 ) eu . set_font ( 'Arial' , 'I' , 8 ) # Adicione um número de página page = 'Page' + str ( self . Page_no ( ) ) + '/ {nb}' self . célula ( 0 , 10 , página, 0 , 0 , 'C' ) def create_pdf ( caminho_pdf ) : pdf = CustomPDF ( ) # Crie o valor especial {nb} pdf. alias_nb_pages ( ) pdf. add_page ( ) pdf. set_font ( 'Times' , '' , 12 ) line_no = 1 para i no intervalo ( 50 ) : pdf. célula ( 0 , 10 , txt = "Linha # {}" . formato ( line_no ) , ln = 1 ) line_no + = 1 pdf. saída ( caminho_pdf ) se __name__ == '__main__' : create_pdf ( 'header_footer.pdf' )
Como esse é um pedaço de código bastante longo, vamos examinar esse item por peça. A primeira seção que queremos examinar é o método do cabeçalho :
def header ( self ) : # Configure um logotipo próprio . auto- imagem ( 'snakehead.jpg' , 10 , 8 , 33 ) . set_font ( 'Arial' , 'B' , 15 ) # Adicione um endereço próprio . célula ( 100 ) auto . células ( 0 , 5 , 'Mike Driscoll' , ln = 1 ) auto . célula ( 100 ) auto . células ( 0 , 5 , '123 American Way' , ln = 1 ) auto . célula ( 100 ) auto . célula ( 0 , 5 , 'Qualquer cidade, EUA', ln = 1 ) # Quebra de linha própria . ln ( 20 )
Aqui, apenas codificamos a imagem do logotipo que queremos usar e, em seguida, definimos a fonte que usaremos em nosso cabeçalho. Em seguida, adicionamos um endereço e posicionamos esse endereço à direita da imagem. Você notará que, quando estiver usando o PyFPDF, a origem é o canto superior esquerdo da página. Portanto, se queremos mover nosso texto para a direita, precisamos criar uma célula com várias unidades de medida. Nesse caso, movemos as próximas três linhas para a direita adicionando uma célula de 100 mm. Em seguida, adicionamos uma quebra de linha no final, que deve adicionar 20 mm de espaço vertical.
Em seguida, queremos substituir o método do rodapé :
def rodapé ( auto ) : auto . set_y ( -10 ) eu . set_font ( 'Arial' , 'I' , 8 ) # Adicione um número de página page = 'Page' + str ( self . Page_no ( ) ) + '/ {nb}' self . célula ( 0 , 10 , página, 0 , 0 , 'C' )
A primeira coisa que fazemos aqui é definir a posição y da origem na página para -10 mm ou -1 cm. Isso coloca a origem do rodapé logo acima da parte inferior da página. Em seguida, definimos nossa fonte para o rodapé. Finalmente, criamos o texto do número da página. Você observará a referência a {nb} . Este é um valor especial no PyFPDF que é inserido quando você chama alias_nb_pages e representa o número total de páginas no documento. A última etapa do rodapé é escrever o texto da página e centralizá-lo.
A parte final do código a ser observada está na função create_pdf :
def create_pdf ( caminho_pdf ) : pdf = CustomPDF ( ) # Crie o valor especial {nb} pdf. alias_nb_pages ( ) pdf. add_page ( ) pdf. set_font ( 'Times' , '' , 12 ) line_no = 1 para i no intervalo ( 50 ) : pdf. célula ( 0 , 10 , txt = "Linha # {}" . formato ( line_no ) , ln = 1 ) line_no + = 1 pdf. saída ( caminho_pdf )
É aqui que chamamos o método um tanto mágico de ** alias_nb_pages ** que nos ajudará a obter o número total de páginas. Também definimos a fonte para a parte da página que não é ocupada pelo cabeçalho ou rodapé. Em seguida, escrevemos 50 linhas de texto no documento para criar um PDF de várias páginas.
Ao executar esse código, você verá uma página parecida com esta:
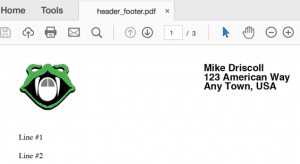
Agora vamos descobrir como você pode criar tabelas com o PyFPDF.
Tabelas
O PyFPDF não possui um controle de tabela. Em vez disso, você deve criar suas tabelas usando células ou HTML. Vamos dar uma olhada em como você pode criar uma tabela usando células primeiro:
# simple_table.py de fpdf import FPDF def tabela simples ( espaçamento = 1 ) : data = [ [ 'Nome' , 'Sobrenome' , 'email' , 'zip' ] , [ 'Mike' , 'Driscoll' , 'mike@somewhere.com' , '55555' ] , [ 'John' , 'Doe' , 'jdoe@doe.com' , '12345' ] , [ 'Nina' , 'Ma' , 'inane@where.com' , '54321' ] ] pdf = FPDF ( ) pdf. set_font ( "Arial" , tamanho = 12 ) pdf. add_page ( ) col_width = pdf. w / 4.5 row_height = pdf. font_size para linha nos dados: para item na linha: pdf. célula ( largura da coluna, altura da linha * espaçamento, txt = item, borda = 1 ) pdf. ln ( altura_da_ linha * espaçamento ) pdf. output ( 'simple_table.pdf' ) se __name__ == '__main__' : simple_table ( )
Aqui, apenas criamos uma lista simples de listas e, em seguida, fazemos um loop sobre ela. Para cada linha na lista e cada elemento na linha aninhada, adicionamos uma célula ao nosso objeto PDF. Observe que ativamos a borda para essas células. Quando terminamos de iterar sobre uma linha, adicionamos uma quebra de linha. Se você deseja que as células tenham mais espaço nas células, pode passar um valor de espaçamento. Quando executei esse script, acabei com uma tabela parecida com esta:
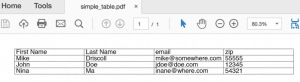
Essa é uma maneira bem simples de criar tabelas. Pessoalmente, prefiro a metodologia do ReportLab aqui.
O método alternativo é usar HTML para criar sua tabela:
# simple_table_html.py de fpdf import FPDF, HTMLMixin classe HTML2PDF ( FPDF, HTMLMixin ) : pass def simple_table_html ( ) : pdf = HTML2PDF ( ) table = "" "<borda da tabela =" 0 "align =" center "width =" 50 % "> <thead> <tr> <th width = " 30 % "> Cabeçalho 1 </th> <th width = " 70 % "> cabeçalho 2 </th> </tr> </thead> <tbody> <tr> <td> célula 1 </td> <td> célula 2 </td> </tr> <tr> <td> célula 2 </td> <td> célula 3 </td> </tr> </tbody> </table> " " " pdf. add_page ( ) pdf. write_html ( tabela ) pdf. output ( 'simple_table_html.pdf' ) se __name__ == '__main__' : simple_table_html ( )
Aqui usamos a classe HTMLMixin do PyFPDF para permitir que ele aceite HTML como entrada e o transforme em PDF. Ao executar este exemplo, você terminará com o seguinte:

Existem alguns exemplos no site que usam a estrutura Web2Py em conjunto com o PyFPDF para criar tabelas com melhor aparência, mas o código estava incompleto, portanto não demonstrarei isso aqui.
Transforme HTML em PDF
O pacote PyFDPF possui algum suporte limitado para tags HTML. Você pode criar títulos, parágrafos e estilos básicos de texto usando HTML. Você também pode adicionar hiperlinks, imagens, listas e tabelas. Verifique a documentação para obter a lista completa de tags e atributos suportados. Você pode pegar o HTML básico e transformá-lo em PDF usando o HTMLMixin que vimos na seção anterior quando criamos nossa tabela.
# html2fpdf.py de fpdf import FPDF, HTMLMixin classe HTML2PDF ( FPDF, HTMLMixin ) : pass def html2pdf ( ) : html = '' '<h1 align = "center"> Demonstração HTML do PyFPDF </h1> <p> Este é um texto comum </p> <p> Você também pode <b> negrito </b>, <i> itálico </i> ou <u> sublinhado </u> ' ' pdf = HTML2PDF ( ) pdf. add_page ( ) pdf. write_html ( html ) pdf. saída ( 'html2pdf.pdf' ) se __name__ == '__main__' : html2pdf ( )
Aqui, usamos apenas a marcação HTML padrão para criar o PDF. Na verdade, acaba ficando muito bom quando você executa esse código:
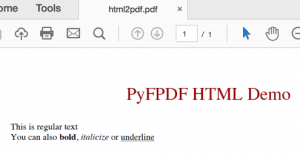
Web2Py
A estrutura Web2Py inclui o pacote PyFPDF para facilitar a criação de relatórios na estrutura. Isso permite criar modelos de PDF no Web2Py. A documentação é um pouco escassa sobre esse assunto, portanto não abordarei esse assunto neste livro. No entanto, parece que você pode fazer relatórios decentes usando o Web2Py dessa maneira.
Modelos
Você também pode criar modelos usando o PyFPDF. O pacote inclui até um script de designer que usa o wxPython para sua interface de usuário. Os modelos que você pode criar seriam onde você deseja especificar onde cada elemento aparece na página, seu estilo (fonte, tamanho, etc.) e o texto padrão a ser usado. O sistema de modelos suporta o uso de arquivos ou bancos de dados CSV. Existe apenas um exemplo na documentação sobre esse assunto, o que é um pouco decepcionante. Embora eu ache que essa parte da biblioteca é promissora, devido à falta de documentação, não me sinto à vontade para escrever sobre isso extensivamente.
Empacotando
O pacote PyFPDF é um projeto bastante interessante que permite a geração básica de PDF. Eles apontam nas perguntas frequentes que não oferecem suporte a gráficos ou widgets ou a um "sistema de layout de página flexível" como o ReportLab. Eles também não oferecem suporte à extração ou conversão de texto em PDF, como PDFMiner ou PyPDF2. No entanto, se tudo o que você precisa é básico para gerar um PDF, essa biblioteca pode funcionar para você. Eu acho que sua curva de aprendizado é mais simples que a do ReportLab. No entanto, o PyFPDF não é nem de longe tão rico em recursos quanto o ReportLab, e eu não senti que você tivesse a mesma granularidade de controle quando se tratava de colocar elementos na página.
Comentários
Postar um comentário