Configuração do mecanismo
O
Engineé o ponto de partida para qualquer aplicativo SQLAlchemy. É a "base" para o banco de dados real e seu DBAPI , entregue ao aplicativo SQLAlchemy por meio de um conjunto de conexões e a Dialect, que descreve como conversar com um tipo específico de combinação de banco de dados / DBAPI.
A estrutura geral pode ser ilustrada da seguinte maneira:
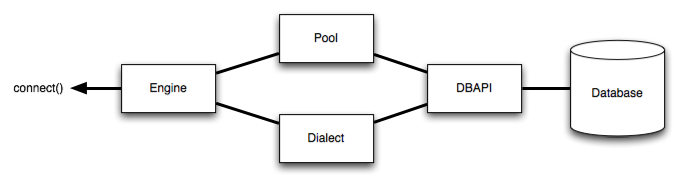
Onde acima, um faz
Enginereferência a Dialecte a Pool, que juntos interpretam as funções do módulo DBAPI, bem como o comportamento do banco de dados.from sqlalchemy import create_engine
engine = create_engine('postgresql://scott:tiger@localhost:5432/mydatabase')
O mecanismo acima cria um
Dialectobjeto adaptado ao PostgreSQL, bem como um Poolobjeto que estabelecerá uma conexão DBAPI no localhost:5432momento em que uma solicitação de conexão for recebida pela primeira vez. Note-se que a Engineea sua subjacente Poolque não estabelecer a primeira ligação DBAPI real até que o Engine.connect() método é chamado, ou uma operação que é dependente deste método tal como Engine.execute()é invocado. Dessa maneira, Enginee Poolpode-se dizer que possui um comportamento de inicialização lento .
O
Engine, uma vez criado, pode ser usado diretamente para interagir com o banco de dados ou pode ser passado para um Sessionobjeto para trabalhar com o ORM. Esta seção cobre os detalhes da configuração de um Engine. A próxima seção, Trabalhando com mecanismos e conexões , detalhará a API de uso do Enginee similares, geralmente para aplicativos não-ORM.Bancos de dados suportados
O SQLAlchemy inclui muitasDialectimplementações para vários back-ends. Dialetos para os bancos de dados mais comuns estão incluídos no SQLAlchemy; alguns outros requerem uma instalação adicional de um dialeto separado.Consulte a seção Dialetos para obter informações sobre os vários back-end disponíveis.
URLs do banco de dados
Acreate_engine()função produz um Engineobjeto com base em uma URL. Esses URLs seguem o RFC-1738 e geralmente podem incluir nome de usuário, senha, nome do host, nome do banco de dados, além de argumentos opcionais de palavras-chave para configurações adicionais. Em alguns casos, um caminho de arquivo é aceito e, em outros, um "nome da fonte de dados" substitui as partes "host" e "banco de dados". A forma típica de uma URL de banco de dados é:dialect+driver://username:password@host:port/database
sqlite, mysql, postgresql, oracle, ou mssql. O nome do driv é o nome da DBAPI a ser usada para conectar-se ao banco de dados usando todas as letras minúsculas. Se não especificado, um DBAPI "padrão" será importado, se disponível - esse padrão geralmente é o driver mais conhecido disponível para esse back-end.Como o URL é como qualquer outro URL, caracteres especiais, como os que podem ser usados na senha, precisam ser codificados em URL. Abaixo está um exemplo de um URL que inclui a senha
"kx%jj5/g":postgresql+pg8000://dbuser:kx%25jj5%2Fg@pghost10/appdb
urllib:>>> import urllib.parse
>>> urllib.parse.quote_plus("kx%jj5/g")
'kx%25jj5%2Fg'
PostgreSQL
O dialeto do PostgreSQL usa psycopg2 como DBAPI padrão. O pg8000 também está disponível como um substituto do Python puro:# default
engine = create_engine('postgresql://scott:tiger@localhost/mydatabase')
# psycopg2
engine = create_engine('postgresql+psycopg2://scott:tiger@localhost/mydatabase')
# pg8000
engine = create_engine('postgresql+pg8000://scott:tiger@localhost/mydatabase')
MySQL
O dialeto do MySQL usa mysql-python como DBAPI padrão. Existem muitos DBAPIs do MySQL disponíveis, incluindo o MySQL-connector-python e o OurSQL:# default
engine = create_engine('mysql://scott:tiger@localhost/foo')
# mysqlclient (a maintained fork of MySQL-Python)
engine = create_engine('mysql+mysqldb://scott:tiger@localhost/foo')
# PyMySQL
engine = create_engine('mysql+pymysql://scott:tiger@localhost/foo')
Oracle
O dialeto Oracle usa cx_oracle como o DBAPI padrão:engine = create_engine('oracle://scott:tiger@127.0.0.1:1521/sidname')
engine = create_engine('oracle+cx_oracle://scott:tiger@tnsname')
Microsoft SQL Server
O dialeto do SQL Server usa pyodbc como DBAPI padrão. pymssql também está disponível:# pyodbc
engine = create_engine('mssql+pyodbc://scott:tiger@mydsn')
# pymssql
engine = create_engine('mssql+pymssql://scott:tiger@hostname:port/dbname')
SQLite
O SQLite se conecta a bancos de dados baseados em arquivos, usando o módulo interno do Pythonsqlite3por padrão.Como o SQLite se conecta aos arquivos locais, o formato da URL é um pouco diferente. A parte "arquivo" da URL é o nome do arquivo do banco de dados. Para um caminho de arquivo relativo, isso requer três barras:
# sqlite://<nohostname>/<path>
# where <path> is relative:
engine = create_engine('sqlite:///foo.db')
# Unix/Mac - 4 initial slashes in total
engine = create_engine('sqlite:////absolute/path/to/foo.db')
# Windows
engine = create_engine('sqlite:///C:\\path\\to\\foo.db')
# Windows alternative using raw string
engine = create_engine(r'sqlite:///C:\path\to\foo.db')
:memory:dados SQLite , especifique um URL vazio:engine = create_engine('sqlite://')
Outros
Consulte Dialetos , a página de nível superior para toda a documentação adicional de dialetos.API de criação de mecanismo
sqlalchemy.create_engine( * args , ** kwargs )- Crie uma nova
Engineinstância.
O formulário de chamada padrão é enviar a URL como o primeiro argumento posicional, geralmente uma sequência que indica o dialeto do banco de dados e os argumentos de conexão:
Argumentos de palavras-chave adicionais podem segui-lo, estabelecendo várias opções nos resultadosengine = create_engine("postgresql://scott:tiger@localhost/test")
Enginee seus subjacentesDialectePoolconstruções:
A forma de cadeia de caracteres do URL éengine = create_engine("mysql://scott:tiger@hostname/dbname", encoding='latin1', echo=True)
dialect[+driver]://user:password@host/dbname[?key=value..], ondedialecté um nome de banco de dados, tais comomysql,oracle,postgresql, etc., edrivero nome de um DBAPI, tais comopsycopg2,pyodbc,cx_oracle, etc. Em alternativa, o URL pode ser um exemplo deURL.
**kwargsrequer uma ampla variedade de opções que são roteadas para seus componentes apropriados. Os argumentos podem ser específicos para oEngine, o subjacenteDialecte oPool. Dialetos específicos também aceitam argumentos de palavras-chave exclusivos desse dialeto. Aqui, descrevemos os parâmetros comuns à maioria doscreate_engine()usos.
Uma vez estabelecido, o recém-resultanteEnginesolicitará uma conexão do subjacentePooluma vezEngine.connect()chamado, ou um método que dependa dele, comoEngine.execute()é chamado. PorPoolsua vez, estabelecerá a primeira conexão DBAPI real quando essa solicitação for recebida. Acreate_engine()chamada em si não estabelece nenhuma conexão DBAPI real diretamente.
- Parâmetros
- case_sensitive = True - se False, os nomes das colunas de resultados corresponderão de maneira que não diferencia maiúsculas de minúsculas, ou seja
row['SomeColumn'],. - connect_args - um dicionário de opções que serão passadas diretamente para o
connect()método da DBAPI como argumentos adicionais de palavras-chave. Veja o exemplo em argumentos DBAPI customizados connect () . - convert_unicode = Falso -
se definido como True, faz com que todos osStringtipos de dados ajam como se oString.convert_unicodesinalizador tivesse sido definido comoTrue, independentemente da configuração deFalseumStringtipo individual . Isso tem o efeito de fazerStringcom que todas as colunas com base acomodem objetos Python Unicode diretamente como se o tipo de dados fosse oUnicodetipo.
Descontinuado desde a versão 1.3: Ocreate_engine.convert_unicodeparâmetro está descontinuado e será removido em uma versão futura. Todas as DBAPIs modernas agora suportam Python Unicode diretamente e esse parâmetro é desnecessário. - criador - um exigível que retorna uma conexão DBAPI. Essa função de criação será passada para o conjunto de conexões subjacente e será usada para criar todas as novas conexões com o banco de dados. O uso dessa função faz com que os parâmetros de conexão especificados no argumento da URL sejam ignorados.
- eco = Falso -
se True, o mecanismo registrará todas as instruções e umarepr()de suas listas de parâmetros no manipulador de log padrão, cujo padrão é asys.stdoutsaída. Se definido como a sequência"debug", as linhas de resultado também serão impressas na saída padrão. Oechoatributo deEnginepode ser modificado a qualquer momento para ativar e desativar o log; O controle direto do log também está disponível usando ologgingmódulo Python padrão .
- echo_pool = False -
se True, o conjunto de conexões registrará a saída informativa, como quando as conexões são invalidadas e quando as conexões são recicladas para o manipulador de log padrão, cujo padrão é asys.stdoutsaída. Se definido como a sequência"debug", o registro incluirá check-out e check-in de pool. O controle direto do log também está disponível usando ologgingmódulo Python padrão .
- empty_in_strategy -
A estratégia de compilação SQL a ser usada ao renderizar uma expressão IN ou NOT IN paraColumnOperators.in_()onde o lado direito é um conjunto vazio. Este é um valor de cadeia que pode ser um dosstatic,dynamicoudynamic_warn. Astaticestratégia é o padrão, e uma comparação IN com um conjunto vazio gerará uma expressão falsa simples “1! = 1”. Adynamicestratégia se comporta como a do SQLAlchemy 1.1 e anterior, emitindo uma expressão falsa do formato "expr! = Expr", que tem o efeito de avaliar para NULL no caso de uma expressão nula.dynamic_warné o mesmo quedynamic, no entanto, também emite um aviso quando um conjunto vazio é encontrado; isso porque a comparação "dinâmica" geralmente apresenta um desempenho ruim na maioria dos bancos de dados.
Novo na versão 1.2: adicionada aempty_in_strategyconfiguração e, adicionalmente, padronizou o comportamento para comparações IN de conjunto vazio a uma expressão booleana estática. - codificação -
O padrão éutf-8. Essa é a codificação de seqüência de caracteres usada pelo SQLAlchemy para operações de codificação / decodificação de seqüência de caracteres que ocorrem no SQLAlchemy, fora do DBAPI. As DBAPIs mais modernas apresentam algum grau de suporte direto aunicodeobjetos Python , o que você vê no Python 2 como uma sequência do formulário . Para os cenários em que o DBAPI é detectado como não suportando um objeto Python , essa codificação é usada para determinar a codificação de origem / destino. Não é usado para os casos em que o DBAPI manipula diretamente o unicode.u'some string'unicode
Para configurar corretamente um sistema para acomodarunicodeobjetos Python , a DBAPI deve ser configurada para manipular o unicode da maneira mais apropriada possível - consulte as notas sobre o unicode pertencentes ao banco de dados de destino específico em uso em Dialects .
As áreas em que a codificação de seqüência de caracteres pode precisar ser acomodada fora do DBAPI incluem zero ou mais de:
- os valores passados para os parâmetros associados, correspondentes ao
Unicodetipo ouStringtipo quandoconvert_unicodeéTrue; - os valores retornados nas colunas do conjunto de resultados correspondentes ao
Unicodetipo ouStringquandoconvert_unicodeéTrue; - a instrução SQL da cadeia de caracteres transmitida ao
cursor.execute()método da DBAPI ; - os nomes das cadeias de caracteres das chaves no dicionário de parâmetros vinculados passados para os DBAPI's
cursor.execute()e para oscursor.setinputsizes()métodos; - os nomes da coluna da sequência recuperados do
cursor.descriptionatributo da DBAPI .
unicodeobjetos Python , que no Python 3 são conhecidos comostr. No Python 2, o DBAPI não especifica o comportamento unicode, portanto, o SQLAlchemy deve tomar decisões para cada um dos valores acima em uma base por DBAPI - as implementações são completamente inconsistentes em seu comportamento.
- os valores passados para os parâmetros associados, correspondentes ao
- activation_options - Opções de execução de dicionário que serão aplicadas a todas as conexões. Vejo
execution_options() - hide_parameters -
Booleano, quando definido como True, os parâmetros da instrução SQL não serão exibidos no log INFO nem serão formatados na representação de seqüência deStatementErrorobjetos.
Novo na versão 1.3.8. - implicit_returning = True - Quando
True, uma construção compatível com RETURNING, se disponível, será usada para buscar novos valores de chave primária gerados quando uma instrução INSERT de uma única linha for emitida sem a cláusula return () existente. Isso se aplica aos back-end que suportam RETURNING ou uma construção compatível, incluindo PostgreSQL, Firebird, Oracle, Microsoft SQL Server. ConfigureFalsepara desativar o uso automático de RETURNING. - isolation_level -
esse parâmetro de cadeia é interpretado por vários dialetos para afetar o nível de isolamento da transação da conexão com o banco de dados. O parâmetro essencialmente aceita algum subconjunto desses argumentos de cadeia:"SERIALIZABLE","REPEATABLE_READ","READ_COMMITTED","READ_UNCOMMITTED"e"AUTOCOMMIT". O comportamento aqui varia de acordo com o back-end e os dialetos individuais devem ser consultados diretamente.
Observe que o nível de isolamento também pode ser definidoConnectiontambém, usando oConnection.execution_options.isolation_levelrecurso.
Veja tambémConnection.default_isolation_level- visualizar nível padrão
Connection.execution_options.isolation_level- definido porConnectionnível de isolamento
Isolamento de Transações SQLite
Isolamento de Transação PostgreSQL
Isolamento de Transação MySQL
Definindo níveis de isolamento de transação - para o ORM - json_deserializer -
para dialetos que suportam oJSONtipo de dados, é uma chamada de Python que converterá uma string JSON em um objeto Python. Por padrão, ajson.loadsfunção Python é usada.
Alterado na versão 1.3.7: O dialeto SQLite renomeou isso de_json_deserializer. - json_serializer -
para dialetos que suportam oJSONtipo de dados, é uma chamada de Python que renderiza um determinado objeto como JSON. Por padrão, ajson.dumpsfunção Python é usada.
Alterado na versão 1.3.7: O dialeto SQLite renomeou isso de_json_serializer. - label_length = None -
valor inteiro opcional que limita o tamanho dos rótulos das colunas geradas dinamicamente a muitos caracteres. Se menor que 6, os rótulos são gerados como "_ (contador)". Se for usadoNoneo valor dedialect.max_identifier_length, que pode ser afetado pelocreate_engine.max_identifier_lengthparâmetro. O valor decreate_engine.label_lengthnão pode ser maior que o decreate_engine.max_identfier_length.
Veja tambémcreate_engine.max_identifier_length - listeners - Uma lista de um ou mais
PoolListenerobjetos que receberão eventos do conjunto de conexões. - logging_name - identificador de string que será usado no campo "nome" dos registros de log gerados no logger "sqlalchemy.engine". O padrão é uma cadeia de caracteres hexadecimal da identificação do objeto.
- max_identifier_length -
inteiro; substitua o max_identifier_length determinado pelo dialeto. seNoneou zero, não tem efeito. Esse é o número máximo configurado de caracteres do banco de dados que pode ser usado em um identificador SQL, como nome da tabela, nome da coluna ou nome do rótulo. Todos os dialetos determinam esse valor automaticamente, no entanto, no caso de uma nova versão do banco de dados para a qual esse valor foi alterado, mas o dialeto de SQLAlchemy não foi ajustado, o valor pode ser passado aqui.
Novo na versão 1.3.9.Veja tambémcreate_engine.label_length - max_overflow = 10 - o número de conexões a serem permitidas no “overflow” do conjunto de conexões, ou seja, as conexões que podem ser abertas acima e além da configuração pool_size, cujo padrão é cinco. isso é usado apenas com
QueuePool. - module = None - referência a um objeto de módulo Python (o próprio módulo, não o nome da string). Especifica um módulo DBAPI alternativo a ser usado pelo dialeto do mecanismo. Cada sub-dialeto faz referência a um DBAPI específico que será importado antes da primeira conexão. Este parâmetro faz com que a importação seja ignorada e o módulo fornecido seja usado. Pode ser usado para testar DBAPIs, bem como para injetar implementações de DBAPI "falsas" no
Engine. - paramstyle = None - O paramstyle a ser usado ao renderizar parâmetros vinculados. O estilo padrão é o recomendado pelo próprio DBAPI, que é recuperado do
.paramstyleatributo do DBAPI. No entanto, a maioria dos DBAPIs aceita mais de um parâmetro e, em particular, pode ser desejável alterar um parâmetro nomeado para um posicional, ou vice-versa. Quando este atributo é passado, deve ser um dos valores"qmark","numeric","named","format"ou"pyformat", e deve corresponder a um estilo de parâmetro conhecido para ser suportado pela DBAPI em utilização. - pool = None - uma instância já construída de
Pool, como umaQueuePoolinstância. Se não for None, esse pool será usado diretamente como o pool de conexão subjacente do mecanismo, ignorando quaisquer parâmetros de conexão presentes no argumento URL. Para obter informações sobre a construção de conjuntos de conexões manualmente, consulte Pool de conexões . - poolclass = None - uma
Poolsubclasse, que será usada para criar uma instância do pool de conexão usando os parâmetros de conexão fornecidos na URL. Observe que isso difere depoolque, na verdade, você não instancia o pool, apenas indica que tipo de pool deve ser usado. - pool_logging_name - identificador de string que será usado no campo "name" dos registros de log gerados no logger "sqlalchemy.pool". O padrão é uma cadeia de caracteres hexadecimal da identificação do objeto.
- pool_pre_ping -
booleano, se True habilitará o recurso de "pré-ping" do conjunto de conexões que testa as conexões quanto à disponibilidade em cada check-out.
Novo na versão 1.2.Veja tambémManipulação de desconexão - pessimista - pool_size = 5 - o número de conexões a serem mantidas abertas dentro do conjunto de conexões. Isso é usado
QueuePooltanto quantoSingletonThreadPool. ComQueuePool, umapool_sizeconfiguração de 0 indica sem limite; para desativar o pool, definapoolclasscomo emNullPoolvez disso. - pool_recycle = -1 -
essa configuração faz com que o pool recicle as conexões após o número especificado de segundos. O padrão é -1 ou nenhum tempo limite. Por exemplo, definir 3600 significa que as conexões serão recicladas após uma hora. Observe que o MySQL, em particular, será desconectado automaticamente se nenhuma atividade for detectada em uma conexão por oito horas (embora isso possa ser configurado com a própria conexão MySQLDB e com a configuração do servidor).
Veja tambémDefinir reciclagem de pool - pool_reset_on_return = 'reversão' -
ajustar oPool.reset_on_returnparâmetro do subjacentePoolobjecto, o qual pode ser ajustado para os valores"rollback","commit", orNone.
Veja tambémPool.reset_on_return - pool_timeout = 30 - número de segundos para esperar antes de desistir de obter uma conexão da piscina. Isso é usado apenas com
QueuePool. - pool_use_lifo = Falso -
use LIFO (último a entrar, primeiro a sair) ao recuperar conexões emQueuePoolvez de FIFO (primeiro a entrar, primeiro a sair). Usando o LIFO, um esquema de tempo limite do servidor pode reduzir o número de conexões usadas durante períodos sem uso de pico. Ao planejar tempos limite do lado do servidor, verifique se há uma estratégia de reciclagem ou pré-ping em uso para lidar com conexões obsoletas normalmente.
Novo na versão 1.3. - plugins -
lista de cadeias de nomes de plugins a serem carregados. Veja oCreateEnginePluginplano de fundo.
Novo na versão 1.2.3. - strategy = 'plain' -
seleciona implementações alternativas de mecanismo. Atualmente disponíveis são:
- a
threadlocalestratégia, descrita em Usando a estratégia de execução local ; - a
mockestratégia, que despacha toda a execução da instrução para uma função passada como argumentoexecutor. Veja o exemplo no FAQ .
- a
- executor = None - uma função que recebe argumentos , para a qual a estratégia despacha toda a execução da instrução. Usado apenas por .
(sql, *multiparams, **params)mockstrategy='mock'
- case_sensitive = True - se False, os nomes das colunas de resultados corresponderão de maneira que não diferencia maiúsculas de minúsculas, ou seja
sqlalchemy.engine_from_config( configuração , prefixo = 'sqlalchemy.' , ** kwargs )- Crie uma nova instância do mecanismo usando um dicionário de configuração.
O dicionário geralmente é produzido a partir de um arquivo de configuração.
As chaves de interesseengine_from_config()devem ser prefixadas, por exemplosqlalchemy.url,sqlalchemy.echoetc. O argumento 'prefix' indica o prefixo a ser pesquisado. Cada chave correspondente (após a remoção do prefixo) é tratada como se fosse o argumento da palavra-chave correspondente a umacreate_engine()chamada.
A única chave necessária é (assumindo o prefixo padrão)sqlalchemy.url, que fornece a URL do banco de dados .
Um conjunto selecionado de argumentos de palavra-chave será "coagido" ao tipo esperado com base nos valores da string. O conjunto de argumentos é extensível por dialeto usando oengine_config_typesacessador.
- Parâmetros
- configuration - Um dicionário (normalmente produzido a partir de um arquivo de configuração, mas isso não é um requisito). Os itens cujas chaves começam com o valor de 'prefix' terão esse prefixo removido e serão passados para create_engine .
- prefixo - Prefixo para corresponder e depois retirar as chaves da 'configuração'.
- kwargs - Cada argumento de palavra-chave
engine_from_config()substitui o item correspondente retirado do dicionário 'configuração'. Os argumentos da palavra-chave não devem ser prefixados.
sqlalchemy.engine.url.make_url( nome_ou_url )- Dada uma instância de cadeia ou unicode, produza uma nova instância de URL.
A sequência especificada é analisada de acordo com as especificações da RFC 1738. Se um objeto de URL existente for passado, apenas retornará o objeto.
- classe
sqlalchemy.engine.url.URL( drivername , nome de usuário = nenhum , senha = nenhum , host = nenhum , porta = nenhum , banco de dados = nenhum , consulta = nenhum ) - Representa os componentes de uma URL usada para conectar-se a um banco de dados.
Este objeto é adequado para ser passado diretamente para umacreate_engine()chamada. Os campos da URL são analisados de uma sequência pelamake_url()função. o formato da string do URL é uma string no estilo RFC-1738.
Todos os parâmetros de inicialização estão disponíveis como atributos públicos.
- Parâmetros
- drivername - o nome do back-end do banco de dados. Esse nome corresponderá a um módulo no sqlalchemy / database ou a um plug-in de terceiros.
- nome de usuário - O nome do usuário.
- senha - senha do banco de dados.
- host - O nome do host.
- port - O número da porta.
- banco de dados - O nome do banco de dados.
- query - Um dicionário de opções a serem passadas para o dialeto e / ou DBAPI na conexão.
get_dialect( )- Retorne a classe de dialeto do banco de dados SQLAlchemy correspondente ao nome do driver desta URL.
translate_connect_args( nomes = [] , ** kw )- Traduzir atributos de URL em um dicionário de argumentos de conexão.
Retorna atributos desse URL ( host , banco de dados , nome de usuário , senha , porta ) como um dicionário simples. Os nomes dos atributos são usados como chaves por padrão. Atributos não definidos ou falsos são omitidos no dicionário final.
- Parâmetros
- ** kw - Nomes de chave alternativos e opcionais para atributos de URL.
- nomes - Descontinuado. O mesmo objetivo que os nomes alternativos baseados em palavras-chave, mas correlaciona o nome ao original em termos posicionais.
Pooling
EleEnginesolicitará ao pool de conexões uma conexão quando os métodos connect()ou execute()forem chamados. O conjunto de conexões padrão,, QueuePoolabrirá conexões com o banco de dados conforme a necessidade. À medida que instruções simultâneas são executadas, QueuePoolseu pool de conexões aumentará para um tamanho padrão de cinco e permitirá um "estouro" padrão de dez. Como a base Engineé essencialmente a base do conjunto de conexões, você deve manter um único Enginepor banco de dados estabelecido em um aplicativo, em vez de criar um novo para cada conexão.
Nota
QueuePoolnão é usado por padrão para mecanismos SQLite. Consulte SQLite para obter detalhes sobre o uso do conjunto de conexões SQLite.Argumentos DBAPI customizados connect ()
Os argumentos personalizados usados ao emitir aconnect()chamada para o DBAPI subjacente podem ser emitidos de três maneiras distintas. Os argumentos baseados em string podem ser transmitidos diretamente da string da URL como argumentos de consulta:db = create_engine('postgresql://scott:tiger@localhost/test?argument1=foo&argument2=bar')
create_engine()também aceita um argumento connect_argsque é um dicionário adicional ao qual será passado connect(). Isso pode ser usado quando argumentos de um tipo diferente de string são necessários e o conector do banco de dados do SQLAlchemy não possui uma lógica de conversão de tipo presente para esse parâmetro:db = create_engine('postgresql://scott:tiger@localhost/test', connect_args = {'argument1':17, 'argument2':'bar'})
creator argumento, que especifica uma chamada que retorna uma conexão DBAPI:def connect():
return psycopg.connect(user='scott', host='localhost')
db = create_engine('postgresql://', creator=connect)
Configurando o Log
O módulo de log padrão do Python é usado para implementar a saída de log informativo e de depuração com o SQLAlchemy. Isso permite que o log do SQLAlchemy se integre de maneira padrão a outros aplicativos e bibliotecas. Há também dois parâmetroscreate_engine.echoe create_engine.echo_pool presente em create_engine()que permitem o registo imediato a sys.stdout para fins de desenvolvimento local; esses parâmetros finalmente interagem com os criadores regulares de Python descritos abaixo.Esta seção pressupõe familiaridade com o módulo de registro vinculado acima. Todo o log realizado pelo SQLAlchemy existe abaixo do
sqlalchemy namespace, conforme usado por logging.getLogger('sqlalchemy'). Quando o log estiver configurado (ou seja, como via logging.basicConfig()), o espaço para nome geral dos registradores SA que podem ser ativados é o seguinte:sqlalchemy.engine- controla eco ecoando. definido comologging.INFOpara saída da consulta SQL,logging.DEBUGpara consulta + saída do conjunto de resultados. Essas configurações são equivalentesecho=Trueeecho="debug"ativadascreate_engine.echo, respectivamente.sqlalchemy.pool- controla o log do conjunto de conexões. definido paralogging.INFOregistrar a invalidação da conexão e reciclar eventos; defina comologging.DEBUGpara registrar adicionalmente todos os check-ins e check-out de pool. Essas configurações são equivalentespool_echo=Trueepool_echo="debug"ativadascreate_engine.echo_pool, respectivamente.sqlalchemy.dialects- controla o log personalizado para dialetos SQL, na medida em que o log é usado em dialetos específicos, o que geralmente é mínimo.sqlalchemy.orm- controla o log de várias funções do ORM na medida em que o log é usado no ORM, o que geralmente é mínimo. Defina comologging.INFOpara registrar algumas informações de nível superior nas configurações do mapeador.
echo=Truesinalizador:import logging
logging.basicConfig()
logging.getLogger('sqlalchemy.engine').setLevel(logging.INFO)
logging.WARNdentro de todo o sqlalchemyespaço para nome, para que nenhuma operação de log ocorra, mesmo em um aplicativo que tenha o log ativado de outra forma.Os
echosinalizadores presentes como argumentos de palavra-chave para create_engine()e outros, bem como a echopropriedade Engineativada, quando configurada como True, tentarão primeiro garantir que o log esteja ativado. Infelizmente, o logging módulo não fornece nenhuma maneira de determinar se a saída já foi configurada (observe que estamos nos referindo se uma configuração de log foi configurada, não apenas que o nível de log está definido). Por esse motivo, qualquer echo=Truesinalizador resultará em uma chamada para o logging.basicConfig()uso de sys.stdout como destino. Ele também configura um formato padrão usando o nome do nível, o carimbo de data e hora e o nome do criador de logs. Observe que essa configuração tem o efeito de ser configurada , além de quaisquer configurações existentes do criador de logs. Portanto, ao usar o log do Python, verifique se todos os sinalizadores de eco estão definidos como False o tempo todo , para evitar linhas de log duplicadas.O nome do criador de logs da instância, como um,
Engine ou Poolusa como padrão uma cadeia de identificadores hexadecimais truncada. Para definir isso com um nome específico, use os argumentos das palavras-chave “logging_name” e “pool_logging_name” com sqlalchemy.create_engine().
Nota
O SQLAlchemy Engineconserva a sobrecarga da chamada de função Python emitindo apenas instruções de log quando o nível de log atual é detectado como logging.INFOou logging.DEBUG. Ele só verifica esse nível quando uma nova conexão é adquirida no pool de conexões. Portanto, ao alterar a configuração de log para um aplicativo já em execução, qualquer um Connectionque esteja ativo no momento ou, mais comumente, um Sessionobjeto que esteja ativo em uma transação, não registrará nenhum SQL de acordo com a nova configuração até que um novo Connection seja adquirido (no caso de Session, isso ocorre após o término da transação atual e o início de uma nova).
Comentários
Postar um comentário